Data Augmentation
Published:
Data Augmentation လုပ်တယ်ဆိုတာကတော့ ကိုယ့်ရဲ့ AI model ကို ပိုပြီး နားလည်အောင် ရှိပြီးသား dataset ကိုမှ modify လုပ်ထားတဲ့ data အသစ်လေးတွေ ထပ်ထည့်တဲ့ technique ဖြစ်ပါတယ် သူ့ကို Unstructured data (images,videos ,text) တွေအတွက်သုံးပါတယ်
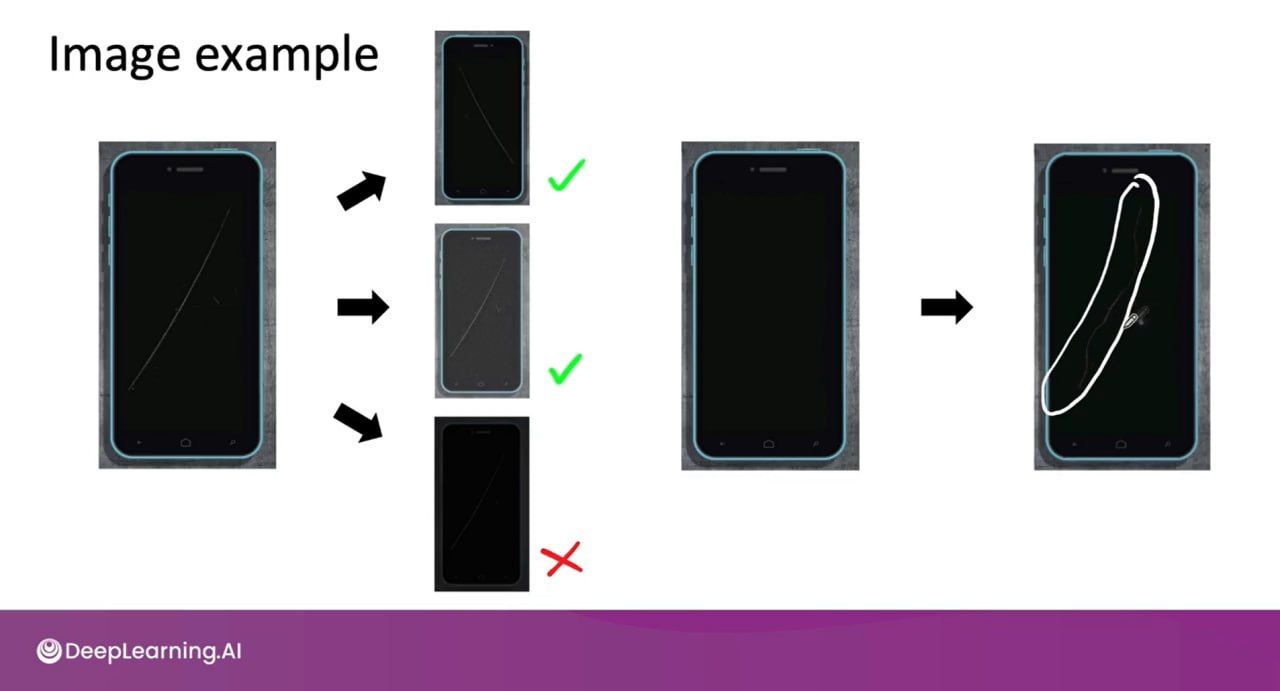
ဥပမာ - Speech Recognition မှာဆိုရင် “Hello” လို့ပြောတဲ့အသံပဲ ထားပါတော့ အဲ့ “Hello” ပြောတဲ့ အသံ ကို ဘေးမှာ noise တွေ ပါခဲ့ရင်တောင် AI က recognize ဖြစ်အောင် မူလ “Hello” အသံနောက်မှာ Music လေးတွေ ထပ်ထည့်တာတို့ လူသံတွေ ထပ်ထည့်တာတို့ လုပ်တာကို Data Augmentation လုပ်တာလို့ခေါ်တယ်
Data တွေ modify လုပ်တဲ့နေရမှာလည်း realistic ဖြစ်ရမယ် အသံဆို တကယ့် လူအစစ်အသံ သီချင်းသံ noise တွေဖြစ်ရမယ် အရမ်း noisy ဖြစ်ပြီး “Hello” အသံပါ ပျောက်လောက်အောင် ကိုယ်ဘာသာ တောင် မခွဲနိုင်တော့တဲ့ အသံ data ဆိုရင်တော့ ကိုယ့် AI model အတွက် ကောင်းတော့မှာမဟုတ်ပါ Data Augmentation လုပ်ရင် သတိထားရမယ့်အချက်တွေဖြစ်ပါတယ်
အဲ့တော့
- Model Train မယ်
- Error analysis လုပ်မယ် ( train ပြီးတော့ ရလာတဲ့ model ရဲ့ weak spot တွေ ရှာမယ်)
- Data Augmentation လုပ်
- Refined လုပ်ထားတဲ့ data နဲ့ ပြန် train ဒါကို Data Iteration loop လုပ်တယ်လို့ခေါ်ပါတယ် အဲ့လို train ခြင်းအားဖြင့် ကိုယ့် AI model ရဲ့ performance ပိုပြီး ကောင်းလာမှာပါ
Reference ကတော့ Andrew Ng ရဲ့ course ပါ Machine Learning in Production